こんにちはニシです。早いもので2024年も2月になりましたね。日々を漫然と過ごしているとあっという間に年を取ってしまいそうですね。
今回はSignate(データ分析コンペのサイト:Kaggleの日本語版みたいなやつです。)のコンペである第2回金融データ活用チャレンジに参加した内容について書きます。
参加した理由
まずそもそもなぜ参加したのかについてですが、主に以下の3点ですかね。
- コンペの題材がビジネス的に興味深かった
- Dataikuをツールとして使用できるようになりたかった
- データ分析コンペをなにかしらやってみたかった
この中で1,2点目が結構重要で、会社の人に興味持ってもらえるのかなーと思えたのが大きいですね。そして、情報系の大学院を卒業している人間としてデータ分析のコンペで成果を上げたいと密かにずっと思ってたんですよね。
コンペの内容
ここからは、第2回金融データ活用チャレンジの内容について書きます。そもそもSIGNATEについてと今回のコンペの概要を記述します。
SIGNATEとは
SIGNATEはデータ分析コンペティションを運営しているサイトです。簡単に言うとKaggleの日本語版みたいな感じですね。Kaggleは基本的に英語のコンペティションですがSIGNATEは日本語なので、日本人の私としてはとっつきやすいです。(なんのために英語も勉強してるかわからいですが。。。)
真面目な話をするとデータ分析のコンペって始めるまで(データ分析環境の準備等)に挫折しやすいのでそこが日本語のコンペだとクリアしやすいので初めての方はSIGNATEからやってみる方が良いと思います。
サイトリンク:https://signate.jp
第2回金融データ活用チャレンジの概要
ここからは、コンペの概要についてです。基本的な情報は以下となります。
| 課題 | 企業向けローンの返済可否予測 |
| データセット | 米国小企業庁のデータをもとに作成した人工データ |
| 評価指標 | MeanF1スコア(F1スコアの正例、負例を入れ替えた平均) |
| スケジュール | 2024/1/18~2024/2/15 |
| 使用できるツール | Dataiku, Databrics, Tableau |
| サポート | 事務局:金融データ活用推進協会 後援:金融庁 |
| その他 | 賞金あり(1位15万, 2位10万, 3位5万) |
賞金付きかつ後援が金融庁となっておりある程度のレベルのコンペなのかなと感じました。また、Dataiku, Databrics, Tableauといったツールの使用も可能となっておりより初心者でも参加しやすいかつビジネスにも転用しやすいいのかなと思います。
データ分析として行った内容
まず前提として、今回参加した理由の1つでもあるのでDataikuを使ってこのコンペに挑戦しました。なので行った分析の実装はすべてDataiku上で行っています。(めちゃ使いやすかったのでデータ分析される方はぜひ使ってみたほうが良いかと思います!)
データ前処理(~機械学習モデルに投入するまで)
コンペ期間中にモデルの学習方法についてはいろいろ試しながらやりましたが最終的にデータの前処理(学習モデルの投入まで)については共通で行っています。
提供されているデータの確認
コンペで提供されているデータはcsv形式です。train.csv(42307件), test.csv(42308件)が配布され、test.csvを0or1で予測して提出をします。データの特徴量は以下の通りです。
| No | 特徴量名 | 説明 |
| 1 | Term | 融資期間 |
| 2 | NoEmp | 融資を受ける前の事業の従業員数 |
| 3 | NewExist | 新規ビジネス化どうか |
| 4 | CreateJob | 企業が融資資金を使用して創出される雇用の数 |
| 5 | RetainedJob | 融資を受けたことで企業が維持すると予想される雇用の数 |
| 6 | FranchiseCode | どのブランドのフランチャイズであるか識別する 一意の5桁コード |
| 7 | RevLineCr | リボルビング信用枠かどうか |
| 8 | LowDoc | 15万ドル未満のローンを1ページの短い申請でできる プログラムかどうか |
| 9 | DisbursementDate | 融資の支払日 |
| 10 | Sector | 産業分類コード |
| 11 | ApprovalDate | 米国小企業庁の承認日 |
| 12 | ApprovalFY | 承認された財務年度 |
| 13 | City | 借り手の会社の所在地(市) |
| 14 | State | 借り手の会社の所在地(州) |
| 15 | BankState | 貸し手の所在地(州) |
| 16 | DisbursementGross | 銀行によって支払われた金額 |
| 17 | GrAppv | 銀行によって承認されたローンの総額 |
| 18 | SBA_Appv | 米国小企業庁が保証する承認されたローンの金額 |
| 19 | UrbanRural | 都会か田舎か(1=都市部、2=田舎、0=未定義) |
この特徴量をもとに貸し倒れするかどうかを予測していきます。
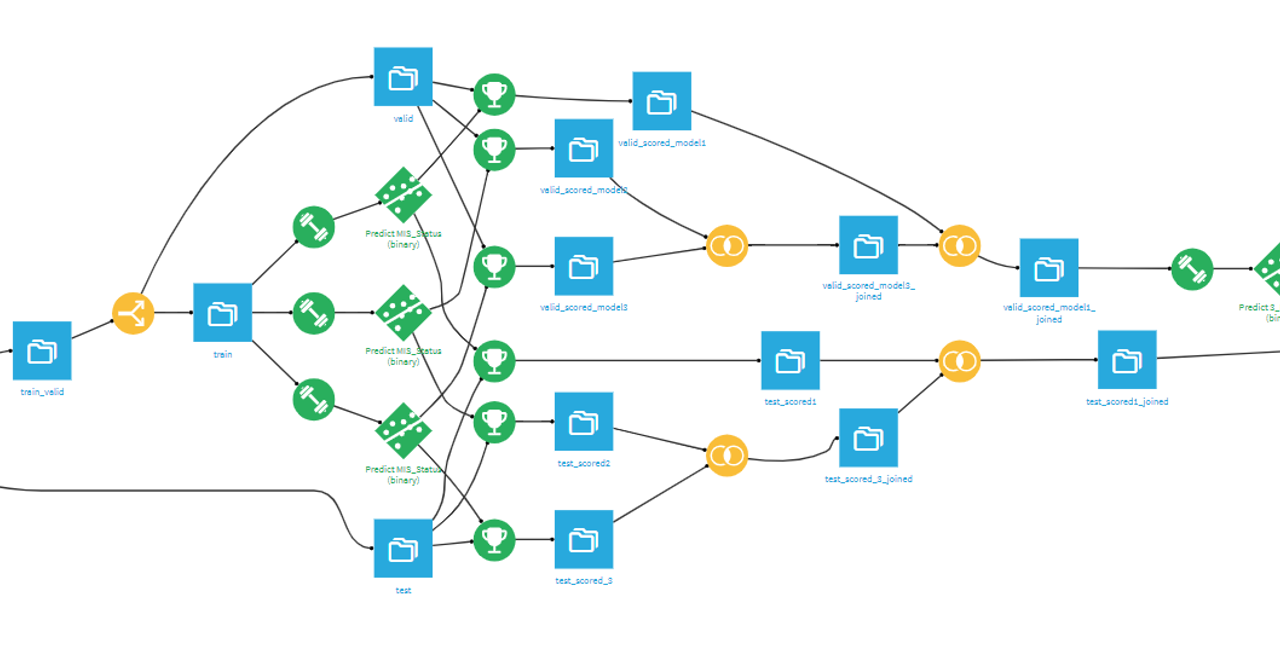
学習データとテストデータまでの前処理として
- trainとtestデータをスタック
- データ加工
- trainとtestデータを分割
を行いました。(Dataikuだと↓みたいな感じです。)
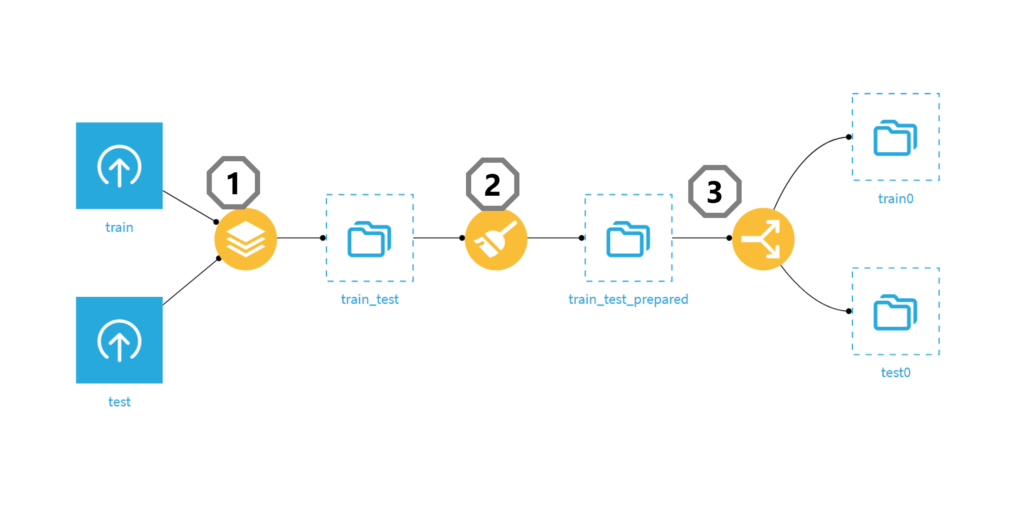
➁のデータ加工の詳細を書くとこんな感じです。
- 日付型に変換(DisbursementData, ApprovalDate)
- 金額表記を数値型に変換(DisbursementGross, GrAppv)
- 欠損値を適当な文字で補完(RevLineCr, LowDoc)
- 欠損値を中央値で補完(DisbursementDate)
- 新しい特徴量を作成(金額系の数値/期間)
- FranchiseCodeからフランチャイズであるかのフラグを作成
結構こういう前処理ってpythonで書くと面倒だし、何をしたのかわからなくなるのですがDataikuは簡単かつ分かりやすくデータ加工ができます。もっと外部データとか財務的に有効な指標とかを作成できればよかったのですが、いまいちドメイン知識が足りず思いつきませんでした。。。。
学習について
単体の学習モデルとしては
- ランダムフォレスト
- Light-GBM
- ロジスティック回帰
を使いました。xGBoostとかCataBoostも使いたかったのですがDataikuの無料版ではできないみたいでした。過去のコンペとかを見る限り、このあたりの学習モデルが使えるのならば十分何とかなりそうでした。
アンサンブルを使った学習について興味があったので、①アンダーサンプリング+バギング➁アンサンブルスタッキングの2種類を実装してみました。
①アンダーサンプリング+バギング
不均衡データを扱うときに有効な手法としてアンダーサンプリング+バギングがあります。めっちゃ簡単にうまくいく理屈を説明すると、分類する境界を決めるときに多数クラスのデータをサンプリングして少数クラスとの境界を決めるという作業を繰り返すと真の境界に近づくことが多いようです。
(詳しくは→https://zenn.dev/kn1kn1/articles/dd54a797cc1972)
ざっくり理論説明はこのくらいにして図解するとこんな感じです。
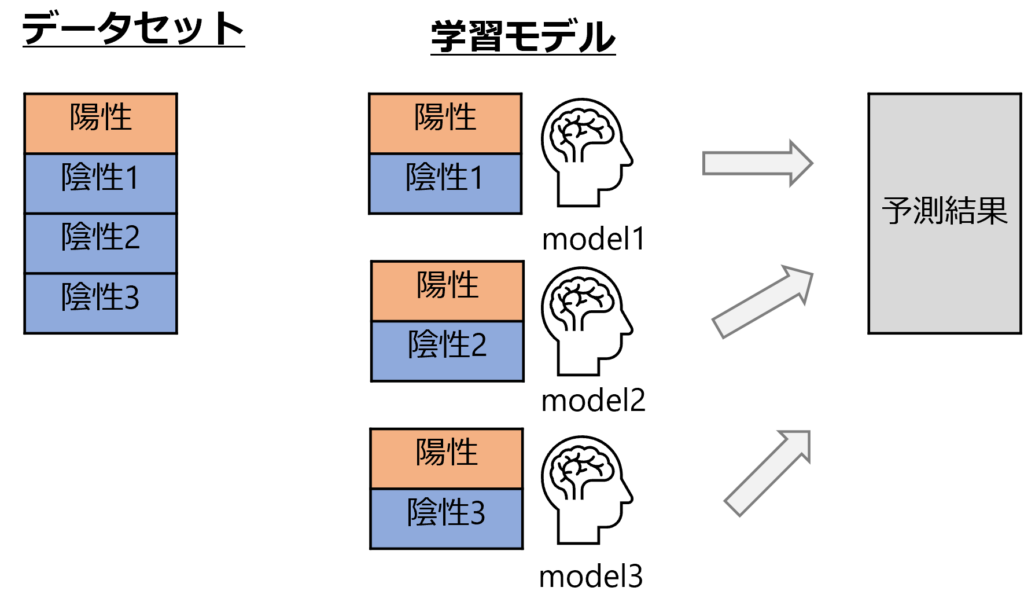
- 少数クラス(図の陽性)はそのまま、多数クラス(図の陰性)をアンダーサンプリングしてデータセットを分割
- 分割したデータセットをそれぞれ学習モデルに投入
- 各モデルの予測の平均を出力結果とする
手順はこんな感じです。Dataikuでポチポチ実装したら意外と簡単にできました。(↓みたいな感じです。)
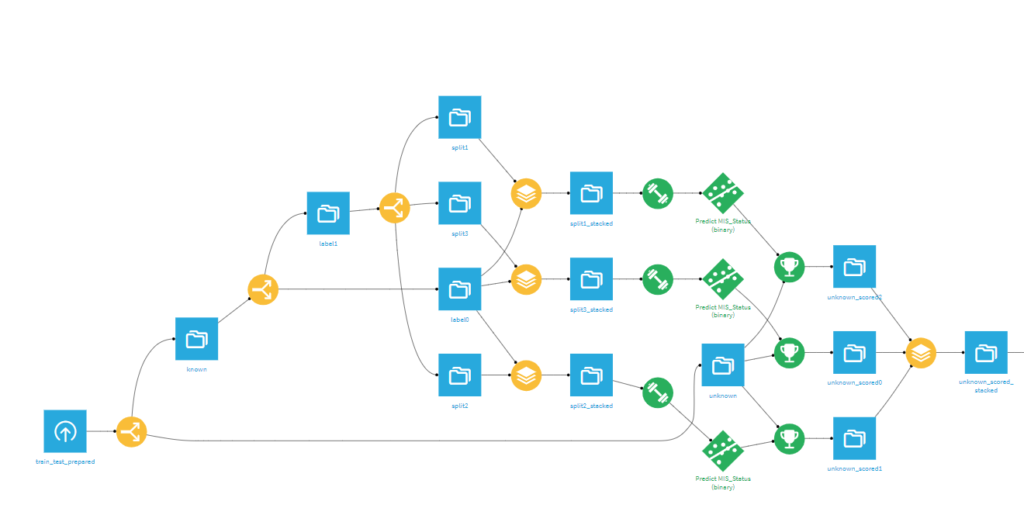
➁アンサンブルスタッキング
機械学習モデルをアンサンブルするのにただ平均をとるのってなんかイケてないと思い色々調べていたらスタッキングっていうやり方に出会いました。
図解してみるとこんな感じですかね。(最近資料化するのって大事だなって思ってるんでできるだけ図とか作ります笑)
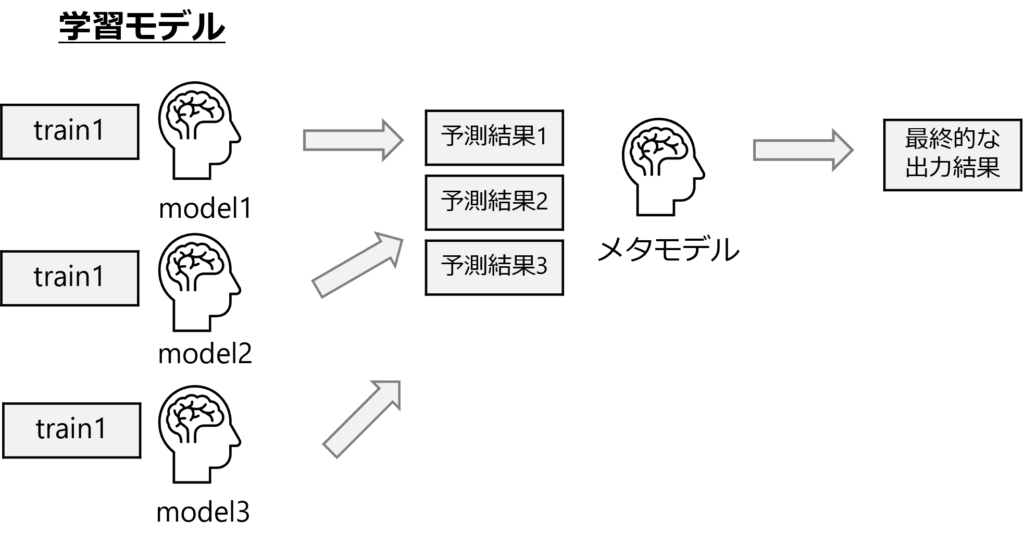
ざっくり手順を説明すると
- 複数のモデルを学習させる
- 各学習モデルの予測結果を線形結合しメタモデルを学習させる
- メタモデルの予測結果を最終的な出力結果とする
こんな感じです。留意事項みたいなことで言うと、最初の学習モデルはできるだけ違うようなモデルにする必要があることと最初の学習モデルの学習データとメタモデルの学習データを分割しておくことです。
最初の学習モデルは予測結果をメタモデルに投入する特性上相関が高いものだと汎化性能が上がらないので違うモデルにする必要があります。
また、学習データの分割は単純にリークして過学習を防ぐために行います。
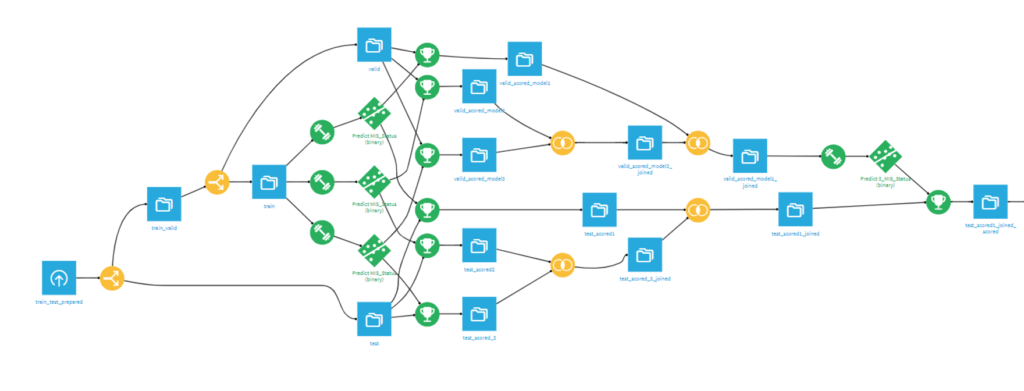
Dataikuで実装すると↓みたいになります。(結構ごちゃついてますね。。)
結果・考察
これまで書いてきたことをやったのですが、なかなか詰まったりすることもあったので結構時間的には使ったと思います。
(平日の仕事終わりと休みの日にちょこちょこ頑張ったのでほめてください笑)
そんな感じで頑張ったコンペですが結果は
221位(1151人中)
でした。(何とも言えない結果ですね)
初参加としては上々というべきなのか、情報系の修士を出てそんなもんかという微妙な順位な気がします。
ちょっと結果の考察がしたいので提出結果を以下にまとめてみました。
| 手法 | 暫定評価 | 最終評価 | 順位* | 提出 |
| ランダムフォレスト | 0.6853156 | 0.6814332 | 221 | ★ |
| スタッキングアンサンブル | 0.6835460 | 0.6812738 | 235 | ★ |
| アンダーサンプリング+バギング | 0.6810778 | 0.6844063 | 76 | |
| RF+LGBMのアンサンブル | 0.6835026 | 0.6845118 | 74 |
こうしてまとめると適切なものを選べていたらメダル圏内(100位)の結果も作れていたみたいです。(提出が2つというルールなので言い訳になりますが笑)
しかし、適切なものを選べるかどうかは実務的にはかなり重要な問題だと思えます。
今回は投稿を繰り返すうちに暫定評価部分にオーバーフィットしたため最終評価でスコアを落としました。実務に置き換えると適切なデータ分割(学習用、検証用、テスト用)とテスト用から知見を得ないように気を配らないと暗黙のリークみたいなことが起きます。
コンペでは運営側でルール設定されるのであまり気にしなくてもいいかもしれませんが、実務においてはデータを当たられた時点で自らルール設定をしなければならないなと実感しました。
まとめ
今回は初挑戦のSIGNATEのコンペについて書きました。しっかり取り組みましたが結果は芳しくありませんでした。しかしながら学べた部分は多かったので次にまた取り組みたいコンペがあれば積極的に参加したいと思います。
実はデータ分析みたいな部分を仕事でしている人間でもあるのでこういった知見はできるだけため込んでいきたいと考えています。
それでは、これからも勉強していきましょう!!


